服务器监控总会设计到内存,cpu相关信息,内存使用对服务器稳定新能至关重要。今天分享一个常用命令,加上相关参数也是排除内存相关问题的好帮手。相关参数记不住参考网上资料做个小笔记。
程序运行时会把数据放到内存里,方便快速调用。一般个人测试机配置偏低都会划出一部分磁盘挂载swap,如果内存不够,程序要么崩溃,要么得去磁盘的swap取数据,而磁盘速度比内存慢100倍以上,自然会卡顿。
一、free 命令
free命令是内存排查的“入门款”,能快速知道“总内存有多少、用了多少、还剩多少”,操作最简单。
在Linux终端输入以下命令,就能查看内存状态:
free

如果想让结果更“人性化”(比如用GB/MB显示,不用记KB),加-h参数;想每隔几秒刷新一次(比如3秒),加-s 3参数:
free -h -s 3
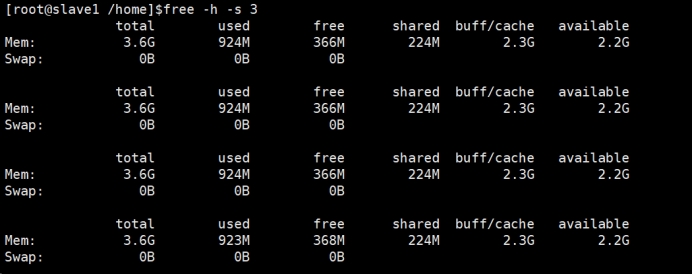
free输出的核心字段,每个都像仓库的“收支数据”:
· Mem:物理内存的“主仓库”,是程序最常用的空间;
· total:主仓库总容量(比如3.6GB);
· used:已用容量(比如924MB);
· free:完全没用到的“空仓库”(比如366MB)——注意:不是“真正可用”,因为还要算缓冲和缓存;
· buff/cache:“临时存储区”,像仓库的“暂存架”:
· buff(缓冲区):刚从磁盘接收的数据,先放这整理(比如刚下载的文件碎片),像快递站的“待分拣区”;
· cache(缓存区):频繁访问的文件/数据,放这方便快速调用(比如常用的程序代码),像家里的“常用物品柜”;
· available:真正能给新程序用的内存(≈free + buff/cache),比如2.2GB——这个值最重要,低于total 的10%就说明内存快不够了。
. Swap:内存的“备用仓库”(磁盘空间),主仓库满了才用,速度慢。
实际场景:判断内存够不够
· 比如用free -h看到available只有200MB(总内存3.6GB),说明内存紧张,可能需要清理缓存或升级内存;
· 如果Swap的used大于0,且持续增加,说明主仓库不够用,已经开始用备用仓库了,得赶紧排查原因。
二、vmstat 命令
vmstat就像是服务器的“全面体检报告”——不仅能看内存,还能查CPU、IO的状态。
在终端输入命令,比如“每隔5秒统计一次,共统计3次”:
vmstat 5 3
参数解释:第一个数字(5)是“统计间隔(秒)”,第二个数字(3)是“统计次数”;
vmstat的输出字段多,但按“模块”理解就简单,每个模块对应一个性能维度:

(1) procs:看“进程排队”情况
· r:正在运行+等待CPU的进程数——如果这个数长期大于服务器CPU核心数(比如4核CPU,r长期大于4),说明CPU不够用,进程要排队;
· b:等待资源的进程数(比如等内存、等磁盘IO)——这个数大于0说明有进程“卡壳”了。
(2) memory:看内存“主仓库+备用仓库”
· swpd:备用仓库(Swap)用了多少(KB)——如果这个数大于0,说明主仓库不够用了,开始用备用仓库;长期大于0且增加,就得升级内存或杀无用进程;
· free:主仓库空容量;
· buff:缓冲区容量(快递待分拣区);
· cache:缓存区容量(常用物品柜),如果值非常大说明缓存文件比较多,而如果此时 io 中的 bi 比较小,就说明文件系统效率比较好。
(3) swap:看备用仓库“存取速度”
· si:每秒从备用仓库(磁盘)读入内存的数据量(KB)——从备用仓库往主仓库运货;
· so:每秒从内存写入备用仓库的数据量(KB)——主仓库放不下,往备用仓库运货;正常情况下si、so都该是0;如果长期大于0(比如持续5分钟都有数值),说明主仓库严重不足,必须解决(升级内存或查内存泄露)。
(4) io:看磁盘“读写速度”
· bi:每秒从磁盘读入数据量(KB);
· bo:每秒写入磁盘数据量(KB);undefined如果bi+bo很大,且后面的wa(IO等待CPU时间)大于20%,说明磁盘IO是瓶颈,内存再大也会卡顿。(5)system:看系统内核“消耗的CPU”
· in:表示某一时间间隔内观测到的每秒设备终端数。
· cs:表示每秒产生的上下文切换次数,这个值要越小越好,太大了,就表示你的CPU大部分浪费在上下文切换,CPU没有充分利用,因此要考虑调低线程或者进程的数目。 注意:这两个值越大,则由内核消耗的CPU就越多。
(5) CPU:看CPU“干活情况”
· us:用户程序用的CPU时间占比——比如订单系统、网页服务这些业务程序;长期大于50%,要优化程序或算法;
· sy:系统内核用的CPU时间占比——比如内存管理、磁盘IO这些系统操作;us+sy最好小于80%,否则CPU不够用;
· id:表示CPU处在空间状态的时间百分比。
· wa:表示IO等待所占用的CPU时间百分比,大于20%说明IO太慢,拖慢整体速度。引起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者监控器的贷款瓶颈(主要是块操作)造成的。
比如某服务器用vmstat 5 3发现:swpd=1GB(备用仓库在用)、si=50KB/s(持续读备用仓库)、wa=25%(IO等得久)——说明内存不够,导致用备用仓库,而备用仓库在磁盘,IO又慢,最后CPU等着IO,形成“连环瓶颈”,这时要先加内存,再查磁盘IO。
三、sar 命令
sar 命令像内存的“定期复查记录”,功能和free类似,但更适合“长期监控”
每5秒采样一次,连续采样3次,监控内存分页:
sar -r 5 3

各字段说明:
. kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间;
. kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间;
. %memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比;
. kbbuffers和kbcached:这两个值就是free命令中的buffer和cache;
. kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap);
. %commit:这个值是kbcommit与内存总量(包括swap)的一个百分比;
. kbactive: 表示当前活跃内存量(单位:KB);这部分内存是最近被访问或使用的内存页,系统会优先保留,除非内存压力极大,否则不会被回收。
. kbinact: 表示当前非活跃内存量(单位:KB);这部分内存是近期未被访问的内存页,当系统需要回收内存时,内核会优先从这部分内存中进行回收,以释放空间给新的内存请求。它代表了系统中“可被清理”的内存缓冲。
. kbdirty:表示脏页大小(单位:KB)。脏页是指数据已被修改并暂存在内存中,但尚未写入磁盘的内存页。
四、内存排查思路
按“先整体、再细节、后长期”的思路来,效率更高:
第一步:用free快速判断“内存够不够”undefined先输free -h,看available(可用内存)占比——大于20%说明内存充足;小于10%说明紧张,需要进一步排查。
第二步:用vmstat找“瓶颈在哪”undefined如果free显示内存紧张,输vmstat 5 3,看swap的si/so(是不是备用仓库在用)、procs的r/b(进程有没有排队)、IO的wa(是不是IO拖慢)——定位是纯内存问题,还是内存+CPU/IO的混合问题。
第三步:用sar做“长期监控”undefined如果想跟踪某程序(比如新上线的APP)的内存消耗,输sar -r 3,持续观察内存变化,看程序是否有“内存泄露”(用着用着内存越来越少)。

